Qué es
Iedra es un buscador y explorador de palabras. Se puede entender como lo opuesto a un diccionario ordinario. En estos, se parte de una palabra para hallar su definición. En Iedra, se parte de una definición y se hallan las palabras que la satisfacen.
Entre los criterios de búsqueda que se pueden usar para buscar palabras están las búsquedas textuales en la propia palabra o en sus definiciones, la longitud de la palabra, el número de sílabas y su acentuación.
Escogiendo bien los términos de búsqueda, Iedra puede servir también como tesauro asociativo, buscador etimológico, buscador de sinónimos, buscador de categorías gramaticales y otras funciones lexicológicas. Puedes echarle un vistazo a los ejemplos de uso para empezar a probar su funcionamiento.
Para buscar en las definiciones, Iedra se vale de las definiciones del Diccionario de la lengua española de la Real Academia Española y del Diccionario de uso del español de María Moliner. En el caso del DLE, al estar en línea, Iedra puede mostrar extractos de los términos que coinciden y enlazar a la definición completa en el sitio de la RAE, análogamente a como lo hacen Google y otros buscadores que enseñan extractos en sus resultados.
Esta herramienta puede resultar de gran utilidad para lingüistas, traductores, escritores, poetas, periodistas y, en general, para gente con inquietud por el español.
Cómo se usa
Todos los términos introducidos importan. Es decir, se usan todos los términos para buscar y solo se muestran resultados que contienen a todos ellos.
Los términos pueden ser palabras sueltas o frases. Las frases deben ir encerradas entre comillas ("").
No se tienen en cuenta las mayúsculas. Es decir, chorizo, Chorizo y ChOrIzO ofrecen los mismos resultados. No obstante, el orden de estos sí puede variar cuando se usa la relevancia como criterio de ordenación.
Búsqueda avanzada
En la parte izquierda de los resultados de búsqueda existen una serie de opciones para modificar el comportamiento de la búsqueda. En Tipo de búsqueda permite activar o desactivar la lematización (más sobre esto abajo). En Buscar en, se puede elegir si buscar en definiciones y lemas (comportamiento por defecto), o solo en los lemas (útil para generar listados de palabras que cumplen un patrón o morfología concretos). En Ordenar, se puede elegir ordenar los resultados de búsqueda por relevancia, por order alfabético, por su frecuencia de aparición en el corpus de Google Ngram y por la longitud del lema.
La relevancia es una puntuación, calculada automáticamente para cada resultado, que intenta medir lo que se ajusta el resultado a los criterios de búsqueda. Se ve afectada por el número de veces que aparecen los términos, la posición en que aparecen, etc.
La frecuencia en Google Ngram mide la cantidad de veces que aparece una palabra en este corpus, que es un conjunto de textos en español, de diversa procedencia. Es decir, mide lo común que es una palabra en el idioma español.
En Año de inclusión, se pueden acotar las palabras resultantes de una búsqueda según el año en que fueron recogidas por primera vez por la RAE. Para ello hay que usar los controles deslizantes para definir un rango de años. Hay que tener en cuenta que muchas palabras no llevan asociada información sobre el año de inclusión, y todas ellas serán excluidas al definir un rango de años, aunque este sea el mayor rango definible (1726-1992). Para anular este filtro, puedes pulsar el botón que aparece a la derecha de los controles deslizantes.
En Longitud del lema, se pueden acotar las palabras según su longitud. El funcionamiento es análogo a los controles deslizantes del Año de inclusión.
En Número de sílabas, se pueden acotar las palabras según (¡oh, sorpresa!) su número de sílabas. El funcionamiento es análogo a los controles deslizantes del Año de inclusión.
Si se quiere excluir un término de los resultados, se le puede poner un signo menos (-) delante. Esto también funciona con las frases entrecomilladas.
En su comportamiento por defecto, el diccionario no solo encuentra las palabras que coinciden exactamente con los términos de búsqueda, sino también las que comparten lexema con ellos (lematización o stemming). Para anular este comportamiento y buscar solo coincidencias exactas, se puede seleccionar el tipo de búsqueda exacta en los resultados de la búsqueda.
Cualquier término de búsqueda, excepto las frases entre comillas, puede contener uno o más comodines en cualquier posición del término. Los comodines indican que el término es, en realidad, un patrón que puede coincidir con muchos términos. Hay dos tipos de comodín: el asterisco (*), que se traduce en cero o más caracteres arbitrarios, y la interrogación (?), que se traduce en exactamente un carácter arbitrario. Este comportamiento es independiente de si está activada o no la búsqueda exacta, aunque normalmente querrás tenerla activada para usar comodines, porque ofrece resultados más predecibles. Por ejemplo, la búsqueda *quete busca todas las palabras que terminan en «quete», la búsqueda cas?o, todas las palabras semejantes que admiten variación en el cuarto carácter («casco» y «casto»), y *cas?o, todas las palabras que terminan según el patrón anterior («agnocasto», «casco», «casto», «entrecasco», «guancasco», «incasto», «monocasco», «pascasio»y «sarcasmo»).
También se pueden hacer búsquedas difusas o por aproximación. Una búsqueda difusa encuentra palabras que son «razonablemente» parecidas al término de búsqueda. Los comodines son una manera estricta de especificar similaridad, ya que se exige que los resultados concuerden exactamente con los caracteres del término. En las búsquedas difusas, también se permite que haya caracteres movidos, eliminados o insertados. Para hacer una búsqueda difusa, basta con colocar una virgulilla (~) detrás de cualquier término de búsqueda (excluyendo las frases). Adicionalmente, se puede especificar un índice de similaridad justo detrás de la virgulilla, que debe ser un número decimal con un punto como separador decimal y dentro del rango que va de 0.0 a 0.999 (si no se especifica, el valor por defecto es 0.5). Al igual que con los comodines, lo más normal es querer activar la búsqueda exacta. Por ejemplo, la búsqueda perro~, exacta y solo en lemas, ofrece más de 100 resultados parecidos a «perro» («berro», «perno», «ferro», «perero», «parro», «cerro»…). La búsqueda perro~0.75 es más estricta y solo ofrece menos de 20 resultados, mientras que perro~0.3 ofrece más de 1000 resultados.
Ejemplos de uso
- Puedes buscar palabras sueltas.
 diccionario, contrario, tienda, Juan, molusco, embutido
diccionario, contrario, tienda, Juan, molusco, embutido - Puedes buscar frases usando comillas. "muy grande", "cuatro ruedas", "esfera celeste", "poco tiempo"
- Así puedes buscar por origen etimológico. "del quechua", "del Sánscr.", "del caló", "loc. lat."
- Así puedes buscar por categoría gramatical. "onomat.", "interj.", "loc. adv. coloq."
- Puedes excluir términos con un signo menos. carruaje -"cuatro ruedas"
Cómo añadir Iedra al navegador
- Chrome
-
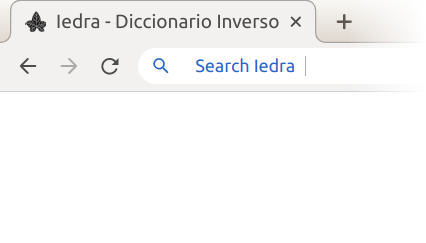
Si usas Chrome y estás leyendo esto, entonces Iedra ya está añadido a tus motores de búsqueda. Chrome detecta automáticamente los motores de búsqueda que visitas y los añade a su lista. Para buscar en Iedra desde la barra de direcciones, escribe “Iedra” y pulsa el tabulador. Iedra quedará seleccionado como el motor de búsqueda y solo tendrás que escribir el término de búsqueda y pulsar Intro. En las opciones del motor de búsqueda de Chrome (puedes acceder escribiendo chrome://settings/searchEngines en la barra de direcciones) puedes administrar la lista de buscadores y seleccionar el que quieres utilizar por defecto (más información).
- Firefox
-
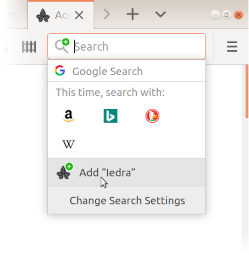
Para añadir Iedra a los motores de búsqueda de Firefox, primero accede a Iedra (si estás leyendo esto, lo más probable es que ya estés dentro). Localiza la barra de búsquedas en la esquina superior derecha del navegador. Aparecerá el icono del buscador por defecto de Firefox. Si pulsas en él, se desplegará una lista con los navegadores alternativos y, debajo, la opción Añadir "Iedra". Al pulsar en ella, Iedra se añadirá a los motores de búsqueda de Firefox y estará siempre disponible para seleccionarlo en el menú desplegable de la barra de búsqueda. Para buscar en Iedra, basta con tenerlo seleccionado en la barra de búsqueda, introducir un término en ella y pulsar Intro. Para más información sobre cómo utilizar y configurar la barra de búsqueda de Firefox, consulta el artículo La barra de búsqueda de la ayuda de Firefox.
Lemarios
- DLE 23.2
- DLE 23.3 (adiciones) (supresiones)
- DLE 23.4 (adiciones) (supresiones)
- DLE 23.5 (incluyendo homógrafos) (adiciones) (supresiones)
- DLE 23.6 (adiciones) (supresiones)
- DLE 23.7 (incluyendo homógrafos) (adiciones) (supresiones)
- DLE 23.8 (incluyendo homógrafos) (adiciones) (supresiones)
Créditos
Este proyecto le debe su existencia al inmenso trabajo académico de la Real Academia Española en la confección de su diccionario y su puesta en disposición al público mediante su buscador en Internet. También gracias al profesor Franz Mayrhofer y su versión mejorada del Diccionario panhispánico de dudas, Iedra puede incluir referencias al DPD entre sus resultados. Los refranes se extraen del Refranero multilingüe del Centro Virtual Cervantes.
Las transcripciones fonéticas y el silabeo están generados con el programa perkins, del doctor Scott Sadowsky. La información sobre la primera aparición de las palabras está extraída del Nuevo tesoro lexicográfico de la lengua española, mediante el script origenes.py. Las gráficas de uso en el tiempo se generan gracias a los datos de Google Ngram, disponibles bajo licencia CC-BY 3.0.
El logotipo usa la tipografía Gabriela, de Eduardo Tunni, con licencia Open Font License. El resto del texto del sitio usa la tipografía IBM Plex Sans, de Mike Abbink y Paul van der Laan, también con licencia Open Font License. La ilustración de la hoja de hiedra está en dominio público y procede del usuario johnny_automatic de Open Clipart. El icono de lupa del botón para buscar es parte del juego de iconos para desarrolladores de WPZOOM (WPZOOM) / CC BY-SA 3.0.
También le debe mucho a @ampajaro, @escalant3, @eumanismo, @inefable, @jesusmagnum, @lorenzogil, @makmonty, @olea, @octete, @pablobm, @teoruiz, @trunks y @versae, por aportar sugerencias y encontrar fallos.